Qwen 2.5 Coder模型部署与应用
1. Qwen 2.5 Coder:你的AI编程闺蜜
各位码农们,准备好迎接你的新编程伙伴了吗?Qwen 2.5 Coder来了!这个由阿里巴巴达摩院精心打造的AI编程助手,不仅能帮你生成代码,还能查漏补缺、推理如流。它就像是你的编程闺蜜,懂你、懂代码,还不会嫌弃你的咖啡口气。

1.1 Qwen 2.5 Coder的超能力
-
多语言支持: Qwen 2.5 Coder支持40多种编程语言。无论你是Python狂热粉,还是JavaScript痴迷者,它都能陪你玩得飞起。
-
代码生成: 只需给它一个简单的提示,它就能为你生成完整的函数、类,甚至是整个程序。就像是给了魔法师一根魔杖,然后 - 嘣!代码就出来了。
-
代码补全: 写到一半卡壳了?别担心,Qwen 2.5 Coder会接着你的思路往下写。它就像是能读懂你心思的编程通灵师。
-
代码修复: 发现bug了但不知道怎么修?Qwen 2.5 Coder可以帮你诊断问题并提供修复方案。它就是你的私人代码医生。
-
代码解释: 看不懂别人的代码?让Qwen 2.5 Coder为你解释。它就像是代码世界的翻译官,能把晦涩难懂的代码翻译成人话。
1.2 为什么选择Qwen 2.5 Coder?
-
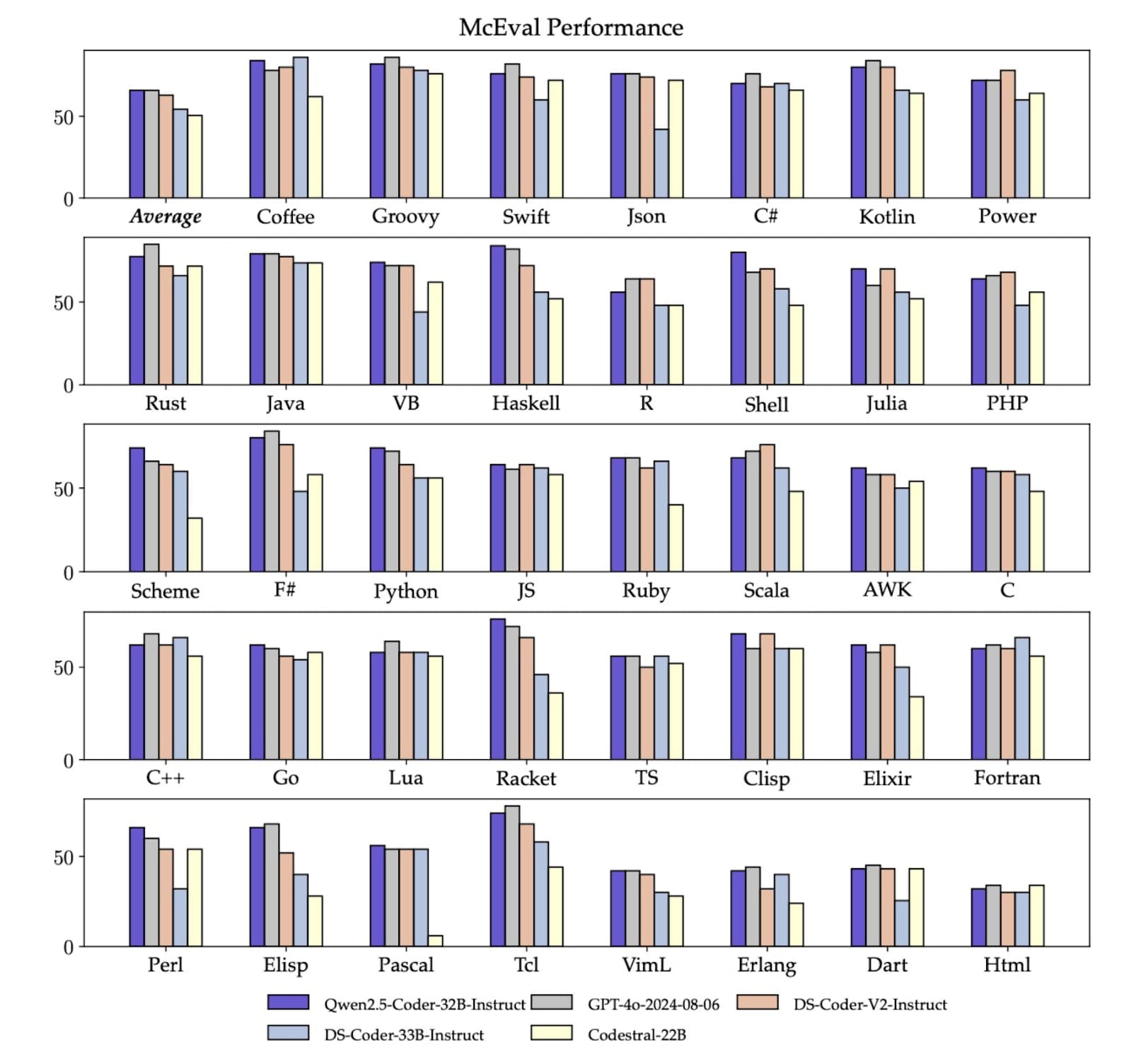
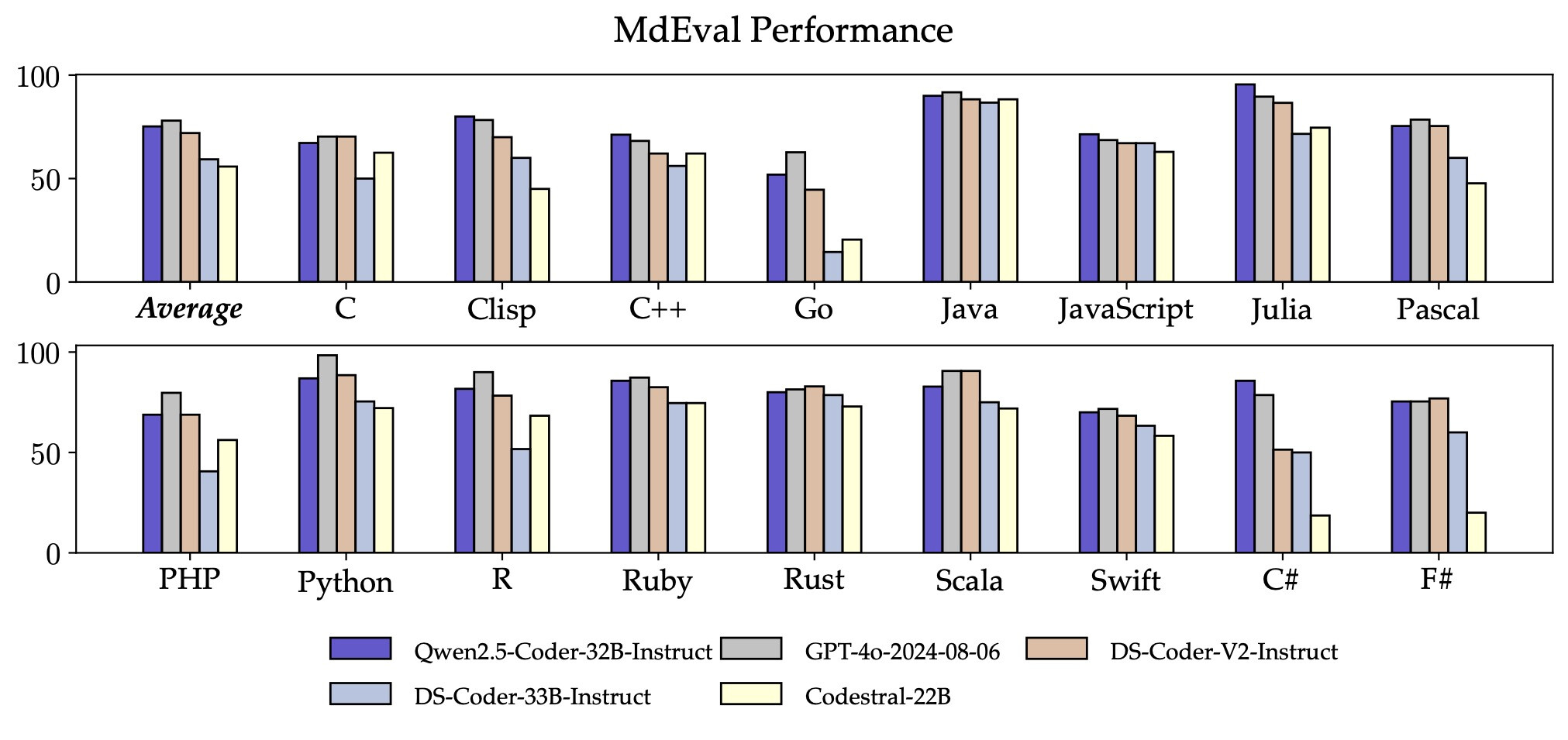
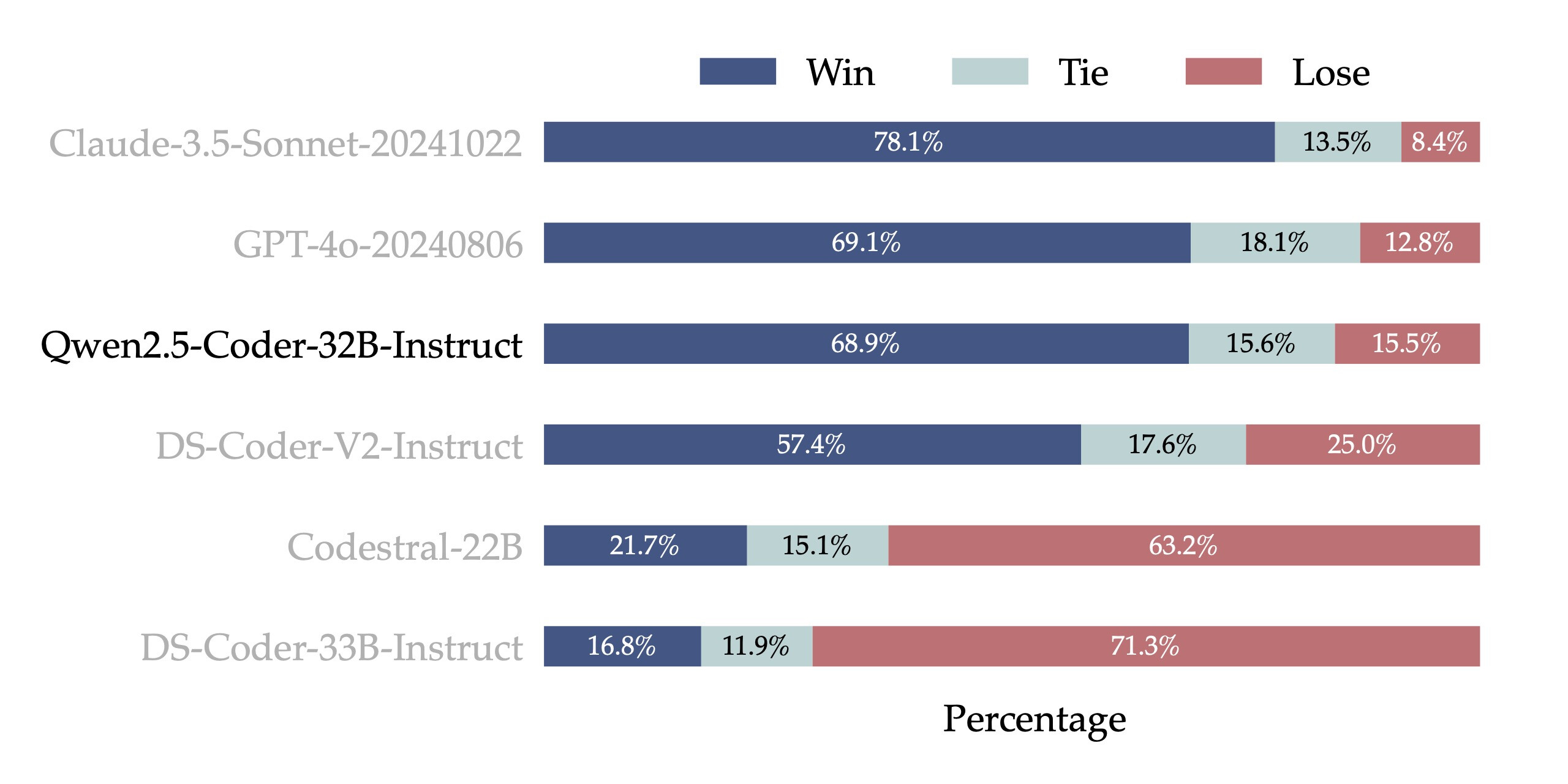
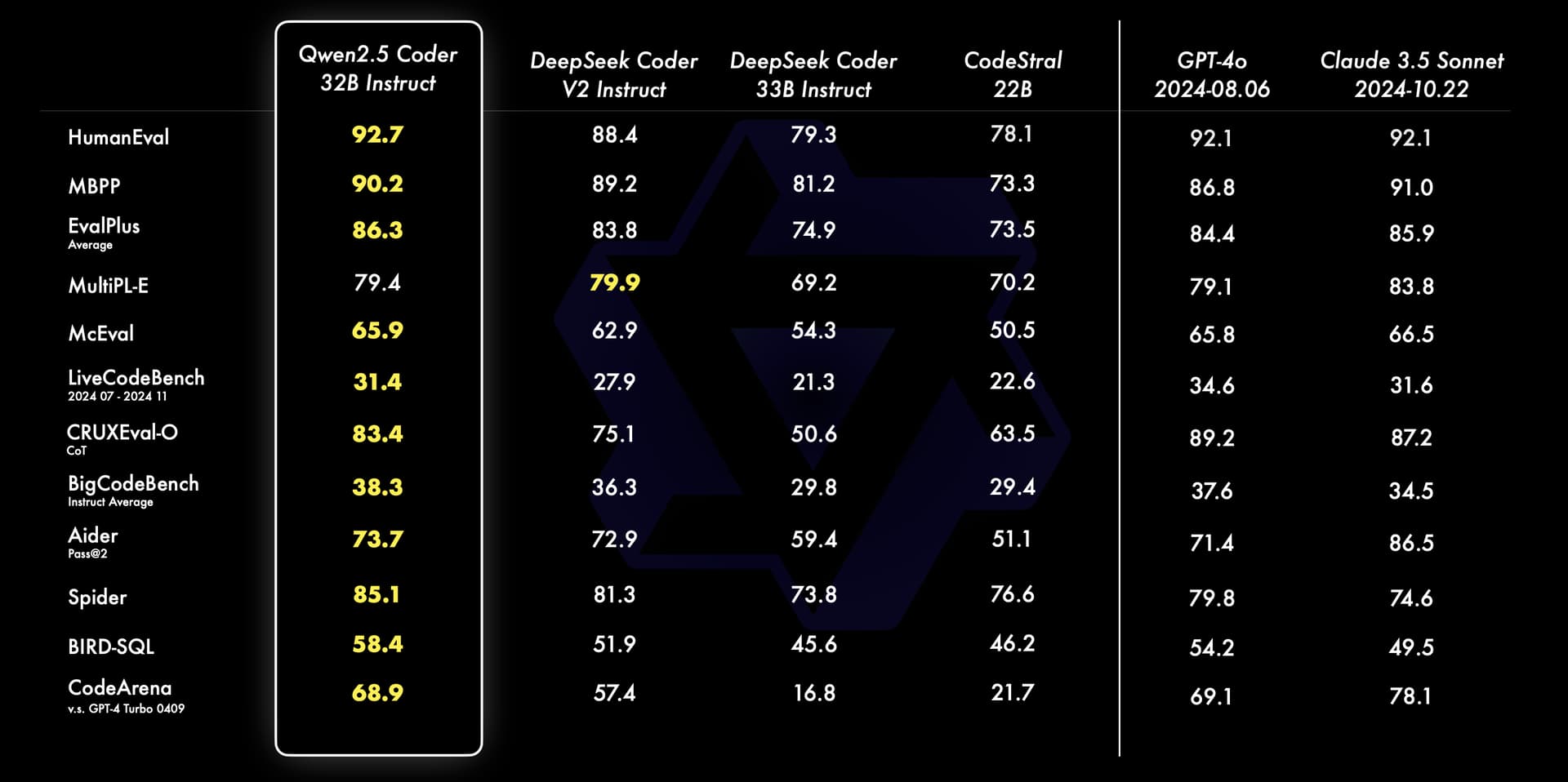
性能卓越: 在多个代码生成基准测试中,Qwen 2.5 Coder的表现可以用"秒杀"来形容。它不仅能写代码,还能写得又快又好。
-
持续学习: Qwen 2.5 Coder不断学习最新的编程技术和最佳实践。用它就像每天都有一个最新版的编程百科全书。
-
开源免费: 是的,你没看错。这么厉害的AI助手,竟然是开源免费的。这大概是程序员界最好的免费午餐了。
好了,介绍完Qwen 2.5 Coder的超能力,我们该开始正式的部署之旅了。系好安全带,准备好你的键盘和咖啡,让我们开始部署吧。
2. 准备工作:给Qwen 2.5 Coder安个温馨小窝
在我们在部署过程之前,让我们先为Qwen 2.5 Coder准备一个舒适的环境。
2.1 硬件要求:不是所有的电脑都能驾驭这位大神
- GPU: NVIDIA A100 40GB或更高。是的,Qwen喜欢豪华的"大床"。如果你只有一张普通的游戏显卡,可能会让Qwen睡得不太舒服。
- CPU: 至少4核。Qwen不是很挑剔,但如果你给她一个双核处理器,她可能会觉得有点"喘不上气"。
- 内存: 最少8GB,推荐16GB或更高。因为Qwen喜欢在内存里跳舞,给她足够的空间让她尽情舞动吧。
感谢Rainyun提供服务器支持
国内4H8G服务器低至45¥/月
Rainyun已有超过五年运营经验,超过30,000个网站在Rainyun运行!

2.2 软件环境:Qwen的口味有点挑
- 操作系统: Ubuntu 20.04 LTS或更高版本。Windows用户别慌,虚拟机欢迎你。或者,你可以考虑给电脑装个双系统,让Qwen住在Ubuntu里。
- Python: 3.8或更高版本。因为Qwen觉得3.7太"老气横秋"了。
- CUDA: 11.3或更高版本。没错,就是那个让你的显卡燃起来的东西。
- cuDNN: 与CUDA版本匹配的版本。就像袜子要配鞋子一样重要。
2.3 环境配置:给Qwen铺张温暖的小床
首先,让我们更新一下系统,就像给Qwen打扫房间一样:
sudo apt update && sudo apt upgrade -ysudo apt update && sudo apt upgrade -y
接下来,安装必要的系统依赖,就像给Qwen准备生活必需品:
sudo apt install -y build-essential cmake unzip pkg-configsudo apt install -y build-essential cmake unzip pkg-config
sudo apt install -y libxmu-dev libxi-dev libglu1-mesa libglu1-mesa-dev
sudo apt install -y libjpeg-dev libpng-dev libtiff-dev
sudo apt install -y libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
sudo apt install -y libxvidcore-dev libx264-dev
sudo apt install -y libopenblas-dev libatlas-base-dev liblapack-dev gfortran
sudo apt install -y libhdf5-serial-dev
sudo apt install -y python3-dev python3-pip python3-venv
现在,让我们为Qwen创建一个舒适的小窝(虚拟环境):
python3 -m venv qwen_envpython3 -m venv qwen_env
source qwen_env/bin/activate
安装PyTorch,就像给Qwen准备一张舒适的大床:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
最后,安装其他必要的Python库,就像给Qwen的房间添加家具:
pip install transformers modelscope flask requests numpy scipypip install transformers modelscope flask requests numpy scipy
验证一下是否安装成功,就像检查Qwen是否睡得舒服:
python -c "import torch; print(torch.cuda.is_available())"python -c "import torch; print(torch.cuda.is_available())"
如果输出为True,恭喜你!Qwen已经躺在舒适的小床上,准备大展身手了。
3. 迎接Qwen 2.5 Coder:把AI大神请回家
3.1 从Hugging Face接Qwen回家
首先,安装git-lfs,就像准备一辆豪华轿车去接Qwen:
sudo apt-get install git-lfssudo apt-get install git-lfs
然后,克隆模型仓库,就像把Qwen接到你家门口:
git lfs installgit lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-Coder-7B
最后,在Python中加载模型,就像邀请Qwen进入你的代码世界:
from transformers import AutoTokenizer, AutoModelForCausalLMfrom transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "./Qwen2.5-Coder-7B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path).to("cuda")
3.2 从ModelScope接Qwen回家
如果你更喜欢ModelScope,那就这样做:
pip install modelscopepip install modelscope
然后在Python中加载模型:
from modelscope.models import Modelfrom modelscope.models import Model
model = Model.from_pretrained("Qwen/Qwen2.5-Coder-7B", device_map="auto")
4. 让Qwen为你服务:搭建本地API
4.1 创建Flask应用:给Qwen一个舞台
首先,创建一个项目目录,就像给Qwen准备一个专属办公室:
mkdir qwen_apimkdir qwen_api
cd qwen_api
然后,创建app.py文件,这就是Qwen的剧本:
touch app.pytouch app.py
现在,用你最喜欢的文本编辑器(vim还是nano?别争了,选你顺手的就行)编辑app.py文件,添加以下内容:
import osimport os
from flask import Flask, request, jsonify
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 设置环境变量以使用GPU,就像给Qwen配了一台超级计算机
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 初始化Flask应用,就像给Qwen一个麦克风
app = Flask(__name__)
# 加载模型和tokenizer,就像给Qwen装备武器
model_path = "./Qwen2.5-Coder-7B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path).to("cuda")
# 设置API密钥,就像给Qwen一个保镖
API_KEY = os.environ.get("QWEN_API_KEY", "your_default_api_key")
def require_api_key(view_function):
def decorated_function(*args, **kwargs):
if request.headers.get('X-API-Key') and request.headers.get('X-API-Key') == API_KEY:
return view_function(*args, **kwargs)
else:
return jsonify({"error": "无效的API密钥"}), 401
return decorated_function
@app.route("/generate_code", methods=["POST"])
@require_api_key
def generate_code():
data = request.json
prompt = data.get("prompt", "")
# 设置生成参数,就像调整Qwen的魔法咒语
max_length = data.get("max_length", 150)
temperature = data.get("temperature", 0.7)
top_p = data.get("top_p", 0.9)
# 生成代码,就像让Qwen施展魔法
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
inputs["input_ids"],
max_length=max_length,
temperature=temperature,
top_p=top_p,
num_return_sequences=1
)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
return jsonify({"generated_code": generated_code})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
4.2 配置和启动API服务:让Qwen开始表演
首先,设置API密钥环境变量,就像给Qwen一个秘密暗号:
export QWEN_API_KEY=your_secure_api_keyexport QWEN_API_KEY=your_secure_api_key
然后,启动Flask应用,让Qwen开始她的表演:
python app.pypython app.py
最后,验证服务是否正常运行,就像给Qwen一个彩排的机会:
curl -X POST http://localhost:5000/generate_code \curl -X POST http://localhost:5000/generate_code \
-H "Content-Type: application/json" \
-H "X-API-Key: your_secure_api_key" \
-d '{"prompt": "def calculate_fibonacci(n):", "max_length": 200, "temperature": 0.8}'
5. 把Qwen搬上网络舞台:Web界面集成
现在Qwen已经在你的本地电脑上安家落户了,是时候让她在更大的舞台上展示才华了。我们来把Qwen集成到一个漂亮的Web界面中,让她可以和全世界的程序员交朋友!
5.1 准备前端项目
首先,我们需要创建一个新的前端项目。我们将使用React来构建我们的Web界面,因为React是目前最流行的前端框架之一,而且Qwen也很喜欢它。
- 创建一个新的React项目:
npx create-react-app qwen-web-uinpx create-react-app qwen-web-ui
cd qwen-web-ui
- 安装必要的依赖:
npm install axios @material-ui/core @material-ui/iconsnpm install axios @material-ui/core @material-ui/icons
5.2 创建主界面
现在,让我们为Qwen创建一个漂亮的主界面。编辑src/App.js文件:
import React, { useState } from 'react';import React, { useState } from 'react';
import {
Container,
TextField,
Button,
Typography,
Paper,
Box
} from '@material-ui/core';
import { Code } from '@material-ui/icons';
import axios from 'axios';
function App() {
const [prompt, setPrompt] = useState('');
const [generatedCode, setGeneratedCode] = useState('');
const [isLoading, setIsLoading] = useState(false);
const handleSubmit = async (e) => {
e.preventDefault();
setIsLoading(true);
try {
const response = await axios.post('http://localhost:5000/generate_code', {
prompt: prompt
}, {
headers: {
'Content-Type': 'application/json',
'X-API-Key': 'your_secure_api_key'
}
});
setGeneratedCode(response.data.generated_code);
} catch (error) {
console.error('Error:', error);
setGeneratedCode('Oops! Something went wrong. Please try again.');
}
setIsLoading(false);
};
return (
<Container maxWidth="md">
<Box my={4}>
<Typography variant="h4" component="h1" gutterBottom>
Qwen 2.5 Coder Web UI
</Typography>
<Paper elevation={3}>
<Box p={3}>
<form onSubmit={handleSubmit}>
<TextField
fullWidth
label="Enter your prompt"
variant="outlined"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
margin="normal"
/>
<Button
type="submit"
variant="contained"
color="primary"
startIcon={<Code />}
disabled={isLoading}
>
{isLoading ? 'Generating...' : 'Generate Code'}
</Button>
</form>
{generatedCode && (
<Box mt={3}>
<Typography variant="h6">Generated Code:</Typography>
<Paper elevation={1}>
<Box p={2}>
<pre>{generatedCode}</pre>
</Box>
</Paper>
</Box>
)}
</Box>
</Paper>
</Box>
</Container>
);
}
export default App;
5.3 解决跨域问题
为了让我们的前端能够成功调用后端API,我们需要解决跨域问题。回到我们的Flask应用(app.py),添加CORS支持:
- 首先,安装Flask-CORS:
pip install flask-corspip install flask-cors
- 然后,修改
app.py:
from flask import Flask, request, jsonifyfrom flask import Flask, request, jsonify
from flask_cors import CORS
# ... 其他导入保持不变
app = Flask(__name__)
CORS(app) # 启用CORS
# ... 其余代码保持不变
5.4 启动全栈应用
现在,我们的全栈应用已经准备就绪!让我们把它们都启动起来。
- 在一个终端中启动后端:
python app.pypython app.py
- 在另一个终端中启动前端:
cd qwen-web-uicd qwen-web-ui
npm start
现在,打开浏览器访问http://localhost:3000,你应该能看到一个漂亮的Web界面,可以输入提示并生成代码了!
6. Qwen的进阶技能:性能优化与高级功能
6.1 模型量化:让Qwen更轻盈
模型量化可以显著减少模型的大小和推理时间,同时保持相当的性能。让我们给Qwen来个"减肥计划":
from transformers import AutoModelForCausalLM, AutoTokenizerfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_path = "./Qwen2.5-Coder-7B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 加载模型并量化
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", torch_dtype=torch.float16)
model = model.quantize(8) # 8位量化
# 保存量化后的模型
model.save_pretrained("./Qwen2.5-Coder-7B-quantized")
现在,你可以使用量化后的模型来减少内存使用和提高推理速度。
6.2 模型微调:让Qwen更懂你
如果你想让Qwen更好地理解你的特定需求,可以考虑对模型进行微调。这里是一个简单的微调示例:
from transformers import Trainer, TrainingArgumentsfrom transformers import Trainer, TrainingArguments
# 准备你的数据集
train_dataset = ... # 你的训练数据
eval_dataset = ... # 你的评估数据
# 设置训练参数
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# 初始化Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
# 开始微调
trainer.train()
# 保存微调后的模型
trainer.save_model("./Qwen2.5-Coder-7B-finetuned")
6.3 批量处理:让Qwen一次处理多个任务
为了提高效率,我们可以让Qwen一次处理多个编程任务。修改我们的app.py:
@app.route("/generate_code_batch", methods=["POST"])@app.route("/generate_code_batch", methods=["POST"])
@require_api_key
def generate_code_batch():
data = request.json
prompts = data.get("prompts", [])
max_length = data.get("max_length", 150)
temperature = data.get("temperature", 0.7)
top_p = data.get("top_p", 0.9)
inputs = tokenizer(prompts, return_tensors="pt", padding=True, truncation=True).to("cuda")
with torch.no_grad():
outputs = model.generate(
inputs["input_ids"],
max_length=max_length,
temperature=temperature,
top_p=top_p,
num_return_sequences=1
)
generated_codes = [tokenizer.decode(output, skip_special_tokens=True) for output in outputs]
return jsonify({"generated_codes": generated_codes})
7. Qwen的安全保镖:监控与安全措施
7.1 日志记录:记录Qwen的一举一动
让我们给Qwen配个私人秘书,记录她的工作日志:
import loggingimport logging
logging.basicConfig(filename='qwen_api.log', level=logging.INFO)
@app.route("/generate_code", methods=["POST"])
@require_api_key
def generate_code():
# ... 前面的代码保持不变 ...
logging.info(f"Received prompt: {prompt}")
# ... 生成代码的逻辑 ...
logging.info(f"Generated code: {generated_code[:50]}...")
return jsonify({"generated_code": generated_code})
7.2 性能监控:给Qwen做个体检
使用Prometheus和Grafana来监控Qwen的"健康状况":
pip install prometheus-flask-exporterpip install prometheus-flask-exporter
然后在app.py中添加:
from prometheus_flask_exporter import PrometheusMetricsfrom prometheus_flask_exporter import PrometheusMetrics
metrics = PrometheusMetrics(app)
# 添加自定义指标
generate_code_counter = metrics.counter(
'generate_code_total', 'Number of code generation requests'
)
@app.route("/generate_code", methods=["POST"])
@require_api_key
@generate_code_counter
def generate_code():
# ... 函数内容保持不变 ...
7.3 安全防护:给Qwen穿上防弹衣
- 使用HTTPS:在生产环境中,务必使用HTTPS来加密API通信。
- 定期更新API密钥:建立一个定期更新API密钥的机制。
- 输入验证:对所有输入进行严格的验证,以防止潜在的注入攻击。
- 限流:实现请求限流机制,以防止API被滥用。
from flask_limiter import Limiterfrom flask_limiter import Limiter
from flask_limiter.util import get_remote_address
limiter = Limiter(
app,
key_func=get_remote_address,
default_limits=["200 per day", "50 per hour"]
)
@app.route("/generate_code", methods=["POST"])
@require_api_key
@limiter.limit("10 per minute")
def generate_code():
# ... 函数内容保持不变 ...
8. 结语:和Qwen一起编程的美好未来
恭喜你!你已经成功地把Qwen 2.5 Coder这个AI大神不仅请到了你的电脑上,还给她搭建了一个漂亮的网络舞台。从此以后,你就有了一个24小时不休息的编程助手。