本文仅为技术测试用途。实际部署中存在诸多变量,结果可能因环境差异而不同,请勿将其视为生产环境的参考依据。
本次测试旨在评估在 2 核 2GB 内存的服务器上运行轻量级 LLM 模型的可行性。
服务器配置
- 实例规格:标准型 SA5(SA5.MEDIUM2)
- 操作系统:Debian 12.10 64 位
- CPU:2 核
- 内存:2 GiB
- 系统盘:50 GiB 通用型 SSD 云硬盘
- 公网带宽:200 Mbps
部署环境
- 推理框架:Ollama v0.15.5
- 测试模型:
gemma3:270m - 测试脚本:https://github.com/lework/llm-benchmark#
普通测试结果
再次提醒:实际部署中存在诸多变量,结果可能因环境差异而不同,请勿将其视为生产环境的参考依据。
100请求1并发
** 粗略总结**
在 2 核 2GB 的服务器上使用 Ollama 部署 gemma3:270m 模型,单并发下可稳定完成全部请求(100/100 成功)。
平均 RPS 为 0.77,平均端到端延迟约 1.3 秒,平均 token 生成速度达 35.8 tokens/s,首 token 响应时间中位数为 0.32 秒。
整体表现符合轻量模型预期,适合低频、非实时场景,但高百分位延迟和生成速度波动提示资源受限明显。
以下为本次测试的详细参数与完整指标:
基本信息:
总请求数: 100 个
成功请求数: 100 个
并发数: 1 个
请求超时: 60 秒
最大输出token数: 50
是否使用长文本: 否
总运行时间: 130.61 秒
每秒请求数 (RPS): 0.77
总输出token数: 4640
模型名称: gemma3:270m
延迟统计 (单位: 秒):
平均延迟: 1.306
延迟 P50: 1.273
延迟 P95: 1.917
延迟 P99: 2.392
Token生成速度 (tokens/sec):
平均速度: 35.81
速度 P50: 39.04
速度 P95: 14.93
速度 P99: 8.08
首token响应时间 (单位: 秒):
平均时间: 0.413
TTFT P50: 0.324
TTFT P95: 0.995
TTFT P99: 1.428
100请求5并发
粗略总结
在 2 核 2GB 服务器上以 5 并发运行 gemma3:270m,100 个请求全部成功。
尽管总运行时间缩短至约 104 秒(RPS 提升至 0.96),但系统资源明显过载:平均延迟飙升至 5.08 秒,首 token 响应时间中位数达 4.36 秒,token 生成速度从单并发时的 ~36 tokens/s 骤降至 9.2 tokens/s,且高百分位性能严重退化(P95 生成速度仅 1.12 tokens/s)。
表明该配置无法有效支撑 5 并发推理,存在显著排队与资源竞争。
以下为本次测试的详细参数与完整指标:
基本信息:
总请求数: 100 个
成功请求数: 100 个
并发数: 5 个
请求超时: 60 秒
最大输出token数: 50
是否使用长文本: 否
总运行时间: 103.67 秒
每秒请求数 (RPS): 0.96
总输出token数: 4607
模型名称: gemma3:270m
延迟统计 (单位: 秒):
平均延迟: 5.076
延迟 P50: 5.186
延迟 P95: 5.786
延迟 P99: 6.756
Token生成速度 (tokens/sec):
平均速度: 9.23
速度 P50: 9.26
速度 P95: 1.12
速度 P99: 1.06
首token响应时间 (单位: 秒):
平均时间: 4.134
TTFT P50: 4.361
TTFT P95: 4.764
TTFT P99: 5.737
100请求20并发
粗略总结
在 2 核 2GB 服务器上以 20 并发运行 gemma3:270m,虽然 100 个请求全部成功且总耗时仅略增至 106.93 秒(RPS ≈ 0.94),但系统已严重过载:平均端到端延迟高达 19.35 秒,首 token 响应时间中位数超过 20 秒,token 生成速度暴跌至 2.72 tokens/s(P99 仅 0.19 tokens/s)。
这表明 Ollama 在高并发下存在显著排队与资源争用,实际响应体验极差。该配置完全不适用于 20 并发场景,建议严格限制并发数(≤1)以保障可用性。
以下为本次测试的详细参数与完整指标:
基本信息:
总请求数: 100 个
成功请求数: 100 个
并发数: 20 个
请求超时: 60 秒
最大输出token数: 50
是否使用长文本: 否
总运行时间: 106.93 秒
每秒请求数 (RPS): 0.94
总输出token数: 4666
模型名称: gemma3:270m
延迟统计 (单位: 秒):
平均延迟: 19.349
延迟 P50: 21.245
延迟 P95: 21.987
延迟 P99: 22.510
Token生成速度 (tokens/sec):
平均速度: 2.72
速度 P50: 2.34
速度 P95: 1.09
速度 P99: 0.19
首token响应时间 (单位: 秒):
平均时间: 18.394
TTFT P50: 20.261
TTFT P95: 21.005
TTFT P99: 21.454
100请求50并发
粗略总结
在 2 核 2GB 服务器上以 50 并发运行 gemma3:270m,尽管所有请求最终成功(100/100),系统已处于严重过载状态:平均延迟高达 42.6 秒,中位数延迟超过 50 秒,接近 60 秒超时阈值;首 token 响应时间 P99 达 58 秒,几乎耗尽整个超时窗口。
Token 生成速度进一步恶化至 1.43 tokens/s(P99 仅 0.05 tokens/s),表明模型几乎无法有效处理并发请求。虽然总吞吐(RPS ≈ 0.9)看似稳定,但这是以极长响应时间为代价的“虚假吞吐”。
该配置完全不适用于实际交互场景,强烈建议避免高并发部署。
以下为本次测试的详细参数与完整指标:
基本信息:
总请求数: 100 个
成功请求数: 100 个
并发数: 50 个
请求超时: 60 秒
最大输出token数: 50
是否使用长文本: 否
总运行时间: 110.71 秒
每秒请求数 (RPS): 0.90
总输出token数: 4786
模型名称: gemma3:270m
延迟统计 (单位: 秒):
平均延迟: 42.607
延迟 P50: 50.951
延迟 P95: 54.631
延迟 P99: 58.089
Token生成速度 (tokens/sec):
平均速度: 1.43
速度 P50: 0.98
速度 P95: 0.87
速度 P99: 0.05
首token响应时间 (单位: 秒):
平均时间: 41.663
TTFT P50: 49.973
TTFT P95: 53.620
TTFT P99: 58.002
100请求100并发
粗略总结
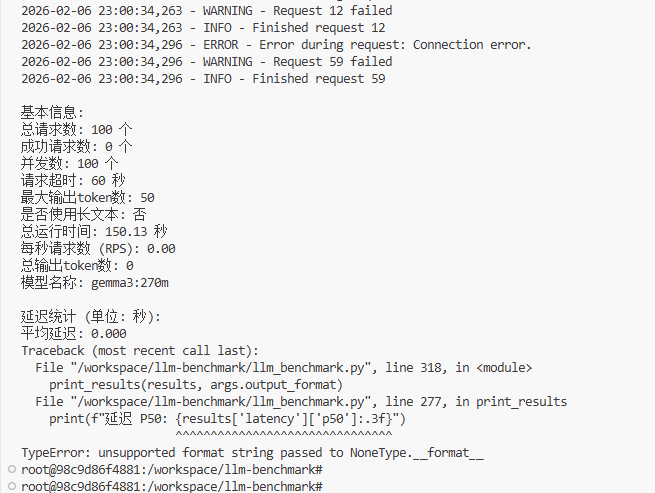
在 100 并发下,gemma3:270m 在 2 核 2GB 服务器上完全无法响应:100 个请求全部失败(成功数为 0),总输出 token 为 0,RPS 为 0。
系统因资源耗尽导致所有请求超时或被拒绝,基准测试脚本甚至因缺乏有效数据而抛出格式化错误(TypeError)。
这表明当前硬件配置远不足以支撑如此高的并发负载,Ollama 服务在此压力下已崩溃或无响应。
以下为本次测试的详细参数与完整指标:
基本信息:
总请求数: 100 个
成功请求数: 0 个
并发数: 100 个
请求超时: 60 秒
最大输出token数: 50
是否使用长文本: 否
总运行时间: 150.13 秒
每秒请求数 (RPS): 0.00
总输出token数: 0
模型名称: gemma3:270m
延迟统计 (单位: 秒):
平均延迟: 0.000
Traceback (most recent call last):
File "/workspace/llm-benchmark/llm_benchmark.py", line 318, in <module>
print_results(results, args.output_format)
File "/workspace/llm-benchmark/llm_benchmark.py", line 277, in print_results
print(f"延迟 P50: {results['latency']['p50']:.3f}")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: unsupported format string passed to NoneType.__format__
root@98c9d86f4881:/workspace/llm-benchmark#
(是的,他自己就崩了,无法测)
稳定性测试
1000请求1并发
粗略总结
在 1 并发、1000 请求的长时间压力测试中,gemma3:270m 在 2 核 2GB 服务器上保持了 100% 成功率,验证了其在低并发下的稳定性。
平均 RPS 为 0.69,平均延迟 1.45 秒,token 生成速度 33.6 tokens/s,与 100 请求测试结果基本一致。
但尾部延迟明显增加(P99 延迟达 4.47 秒,TTFT P99 达 3.55 秒),表明长时间运行下系统可能出现轻微资源累积压力或调度波动。
整体仍适合低频、稳定推理任务,但对响应一致性要求高的场景需谨慎。
以下为本次测试的详细参数与完整指标:
基本信息:
总请求数: 1000 个
成功请求数: 1000 个
并发数: 1 个
请求超时: 60 秒
最大输出token数: 50
是否使用长文本: 否
总运行时间: 1451.98 秒
每秒请求数 (RPS): 0.69
总输出token数: 46130
模型名称: gemma3:270m
延迟统计 (单位: 秒):
平均延迟: 1.452
延迟 P50: 1.289
延迟 P95: 2.367
延迟 P99: 4.470
Token生成速度 (tokens/sec):
平均速度: 33.61
速度 P50: 38.46
速度 P95: 9.70
速度 P99: 4.45
首token响应时间 (单位: 秒):
平均时间: 0.560
TTFT P50: 0.335
TTFT P95: 1.401
TTFT P99: 3.549
1000请求10并发
粗略总结
在 10 并发、1000 请求的压力测试中,gemma3:270m 仍保持 100% 成功率,总耗时约 1030 秒(RPS ≈ 0.97),吞吐量接近单并发水平。然而,系统资源严重受限:平均延迟高达 10.26 秒,首 token 响应时间中位数达 9.29 秒,token 生成速度降至 4.49 tokens/s,且高百分位性能急剧恶化(P95 生成速度仅 0.53 tokens/s)。
这表明 Ollama 在 2 核 2GB 环境下虽能“完成”10 并发任务,但所有请求几乎完全串行化排队处理,实际响应体验极差。
适用于对延迟不敏感的批量离线任务,但绝不适合交互式场景。
以下为本次测试的详细参数与完整指标:
基本信息:
总请求数: 1000 个
成功请求数: 1000 个
并发数: 10 个
请求超时: 60 秒
最大输出token数: 50
是否使用长文本: 否
总运行时间: 1030.26 秒
每秒请求数 (RPS): 0.97
总输出token数: 45910
模型名称: gemma3:270m
延迟统计 (单位: 秒):
平均延迟: 10.259
延迟 P50: 10.251
延迟 P95: 11.098
延迟 P99: 12.072
Token生成速度 (tokens/sec):
平均速度: 4.49
速度 P50: 4.74
速度 P95: 0.53
速度 P99: 0.32
首token响应时间 (单位: 秒):
平均时间: 9.315
TTFT P50: 9.286
TTFT P95: 10.085
TTFT P99: 11.018
结语
本次测试主要测试了270M量级模型在Ollama推理框架下在2核2g服务器测试的表现。结果清晰表明:
- 单并发(≤1)场景下,模型运行稳定、响应及时,可满足低频、非实时的本地推理需求;
- 一旦并发数 ≥5,系统资源迅速成为瓶颈,延迟急剧上升、生成速度断崖式下跌,用户体验显著恶化;
- 高并发(≥20)时,尽管部分请求仍能“成功”,但响应时间接近或逼近超时阈值,实际已丧失可用性;
- 极端并发(100)直接导致服务不可用,验证了该硬件配置的承载上限极低。
(后在稳定性测试中,实际在50并发时就存在极大崩溃的概率。结果未写在文章中)
综上,在此类轻量级服务器上部署 LLM,必须严格限制并发数(建议 ≤1),并明确区分“能跑”和“能用”的边界。
再次强调:本文仅为技术探索性质的测试,实际生产环境受网络、系统负载、模型实现、操作系统调优等多重因素影响,切勿直接套用本结果做架构决策。