使用前提
- 有一个雨云账号,还没有的快点击雨云
代码 - 看注释,填入账号密码就可以用了。
- 半成品,有空再改改。
2023-01-16
获取可领积分(主要目的是每日签到)
半成品,每次签到都重新登录有点憨,得改改
import requests,json,re
登录
def lgoin(field,password):
login_url = "https://api.v2.rainyun.com/user/login"
he = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.52",
"origin": "https://app.rainyun.com",
"x-csrf-token": "undefined"
}
da = {"field":field,"password":password}
r = requests.post(url=login_url,headers=he,json=da)
set_cookie = r.headers['Set-Cookie']
X_CSRF_Token = re.findall(".*?, X-CSRF-Token=(.*?); .*?",set_cookie)[0]
rel = json.loads(r.text)
if rel['data'] == "ok":
rel['set_cookie'] = set_cookie
rel['X_CSRF_Token'] = X_CSRF_Token
else:
rel['set_cookie'] = ""
rel['X_CSRF_Token'] = ""
return rel
获取任务列表
def get_tasks(set_cookie,X_CSRF_Token):
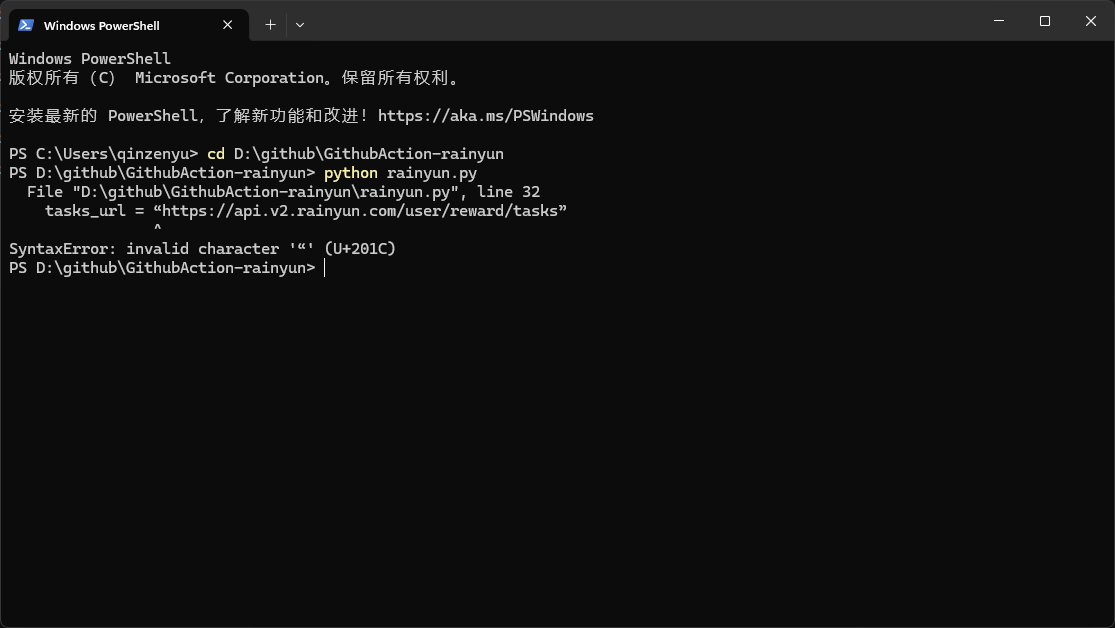
tasks_url = “https://api.v2.rainyun.com/user/reward/tasks”
he = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.52",
"origin": "https://app.rainyun.com",
"x-csrf-token": X_CSRF_Token,
"cookie": set_cookie
}
r = requests.get(url=tasks_url,headers=he)
# 任务状态:1可领,0未完成,2已完成
# print(r.text)
# {"code":200,"data":[{"Name":"每日签到","Detail":"每日登录雨云即可获得奖励!点击领取奖励吧!","Points":300,"Status":1},{"Name":"绑定邮箱","Detail":"邮箱绑定是加入雨云的重要一步,完成邮箱绑定即可完成本任务!","Points":1000,"Status":0},{"Name":"绑定手机","Detail":"手机绑定是加入雨云的重要一步,完成手机绑定即可完成本任务!","Points":2000,"Status":0},{"Name":"绑定QQ","Detail":"绑定QQ后即可快捷登录,完成QQ绑定即可完成本任务!","Points":1000,"Status":0},{"Name":"绑定微信","Detail":"绑定微信后即可快捷登录,完成微信绑定即可完成本任务!","Points":2000,"Status":0},{"Name":"加入Q群","Detail":"关注Q群是了解雨 云活动公告的最佳途径!加入任意官方Q群输入置顶公告内的积分任务密码即可完成本任务!","Points":500,"Status":2}]}
t0 = []
t1 = []
t2 = []
for n in json.loads(r.text)["data"]:
if n['Status'] == 0:
t0.append({"Name":n['Name'],"Points":n['Points'],"Status":n['Status']})
elif n['Status'] == 1:
t1.append({"Name":n['Name'],"Points":n['Points'],"Status":n['Status']})
elif n['Status'] == 2:
t2.append({"Name":n['Name'],"Points":n['Points'],"Status":n['Status']})
print(t0)
print(t1)
print(t2)
rel = {"t0":t0,"t1":t1,"t2":t2}
return rel
获取所有可领积分
def get_f(t1_list,set_cookie,X_CSRF_Token):
he = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.52",
"origin": "https://app.rainyun.com",
"x-csrf-token": X_CSRF_Token,
"cookie": set_cookie
}
tasks_url = "https://api.v2.rainyun.com/user/reward/tasks"
for nn in t1_list:
da = {"task_name":nn['Name'],"verifyCode":""}
r = requests.post(url=tasks_url,headers=he,json=da)
# print(r.text)
# {"code":200,"data":"ok"}
填入用户名,密码
rl = lgoin(“”,“”)
rl2 = get_tasks(rl[“set_cookie”],rl[“X_CSRF_Token”])
rl3 = get_f(rl2[“t1”],rl[“set_cookie”],rl[“X_CSRF_Token”])
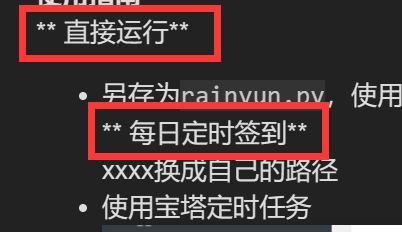
使用指南
** 直接运行**
- 另存为
rainyun.py,使用python3 rainyun.py或python3 rainyun.py运行
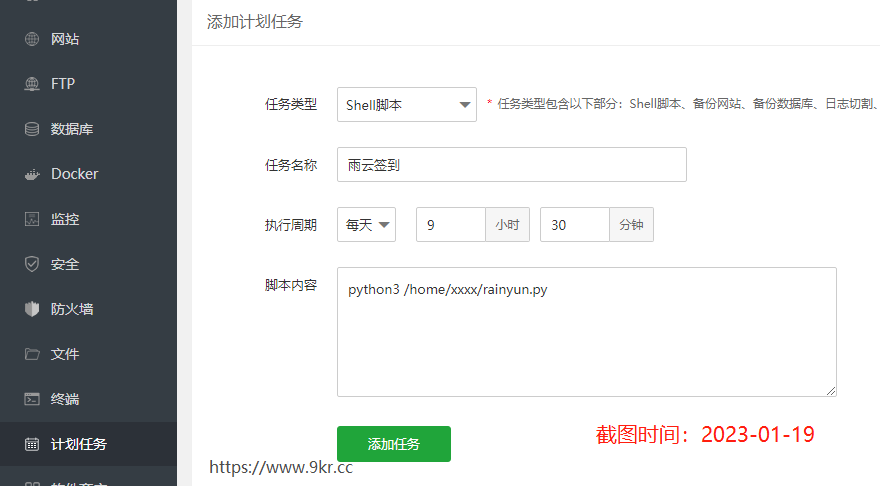
** 每日定时签到**
xxxx换成自己的路径 - 使用宝塔定时任务
- 使用Linux自带的crontab
30 9 * * * python3 /home/xxxx/rainyun.py